Making the K3s cluster control plane HA
I’ll admit, I haven’t been running the K3s control plane in HA. The architecture of 1 control plane node and 3 worker nodes is from a time when every node was running physically on Raspberry Pis. I then gradually migrated to VMs with no changes to the architecture.
There are a few reasons this is starting to become important:
- The nodes are long overdue for an update from Ubuntu 20.04 to Ubuntu 24.04
- In Ubuntu 20.04, the kernel version (
5.15.x) can cause issues when upgrading to Longhorn version1.6.x - Upgrading the cluster, while still mostly automated, is still a risk without HA and requires more planning
- Live migration of the control plane node VM between Proxmox hosts causes unknown behaviour at times
The new Proxmox host (Proxmox host 3) ensures I now have the physical resources required.
So here’s the plan:
- Add a load balancer in front of the control plane
- Change the existing single-node cluster to HA with embedded etcd
IP address assignments:
| IP address | Host |
|---|---|
10.0.3.100 |
Load Balancer frontend VIP |
10.0.3.2 |
k8s-control-1 |
10.0.3.7 |
k8s-control-2 |
10.0.3.8 |
k8s-control-3 |
Setting up the HAProxy plugin in OPNsense as the load balancer
I could spin up 2 VMs to create a HAProxy load balancer setup with failover like in the official documentation. I can also use the OPNsense HAProxy plugin.
While I prefer IaC and configuration in code, I opted for using OPNsense. The physical host of OPNsense is currently underutilized, and it would be nice to get more capabilities out of it.
I won’t go into the specifics of the HAProxy plugin itself. See the official documentation for more information. Some of the screenshots were taken after the setup was confirmed working so the titles sometimes display “Edit” as opposed to “New”.
Installing the plugin was fairly straightforward:

Once installed, the Services list is updated:
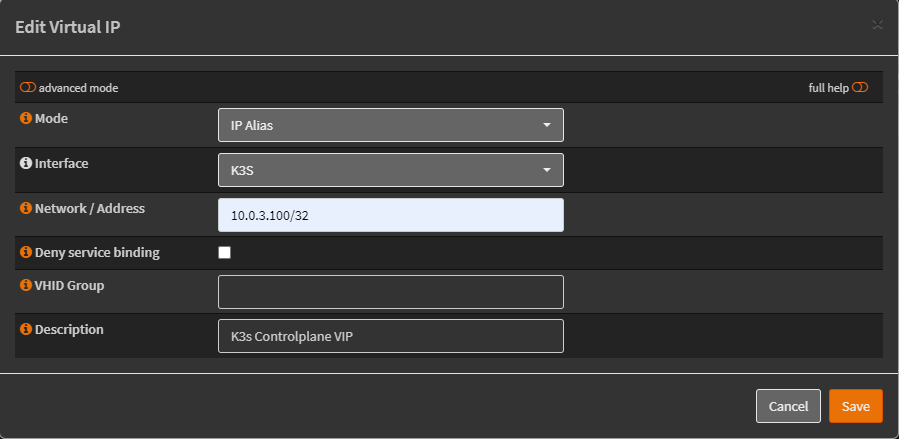
The VIP is defined as an IP Alias. I added this to the existing VLAN interface of the K3s cluster:
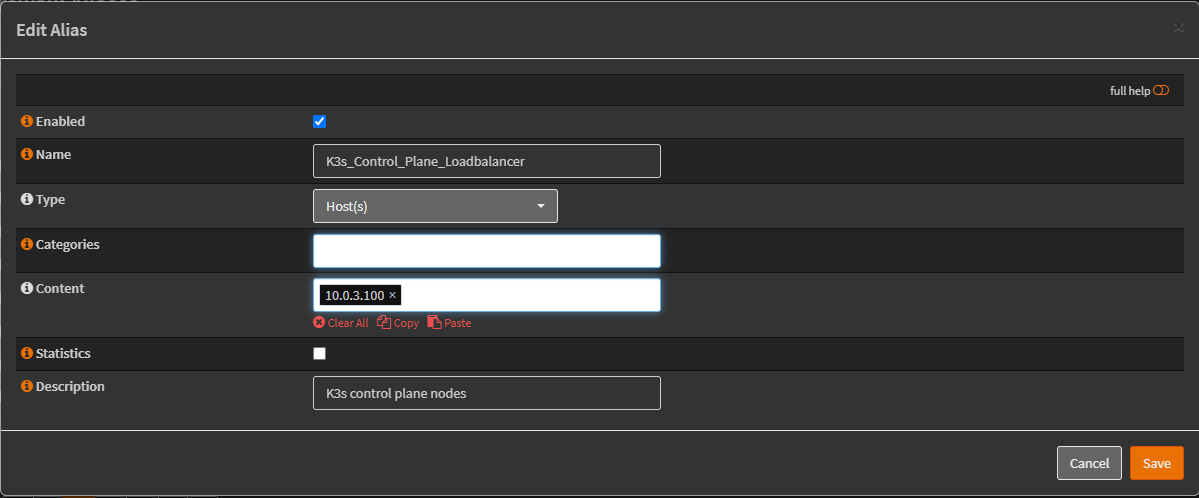
The VIP was added to a firewall alias K3s_Control_Plane_Loadbalancer:
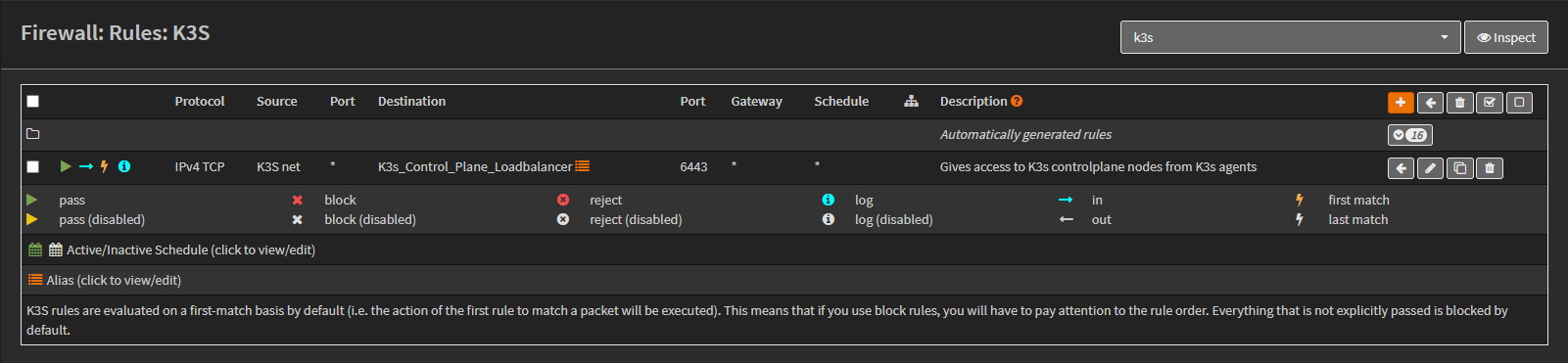
A new firewall rule was created on the K3s interface to allow traffic to the VIP from the worker nodes:
What I’m doing from this point on is more or less copying the HAProxy configuration from the documentation into OPNsense. I also used information from this forum post.
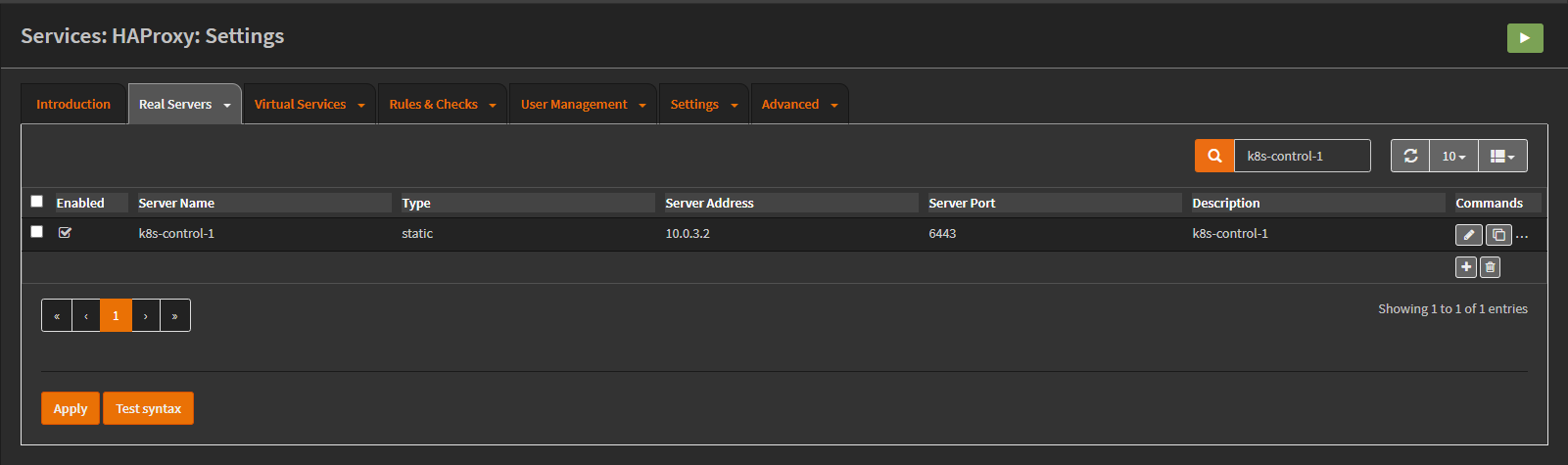
Adding the existing control plane host as a server:
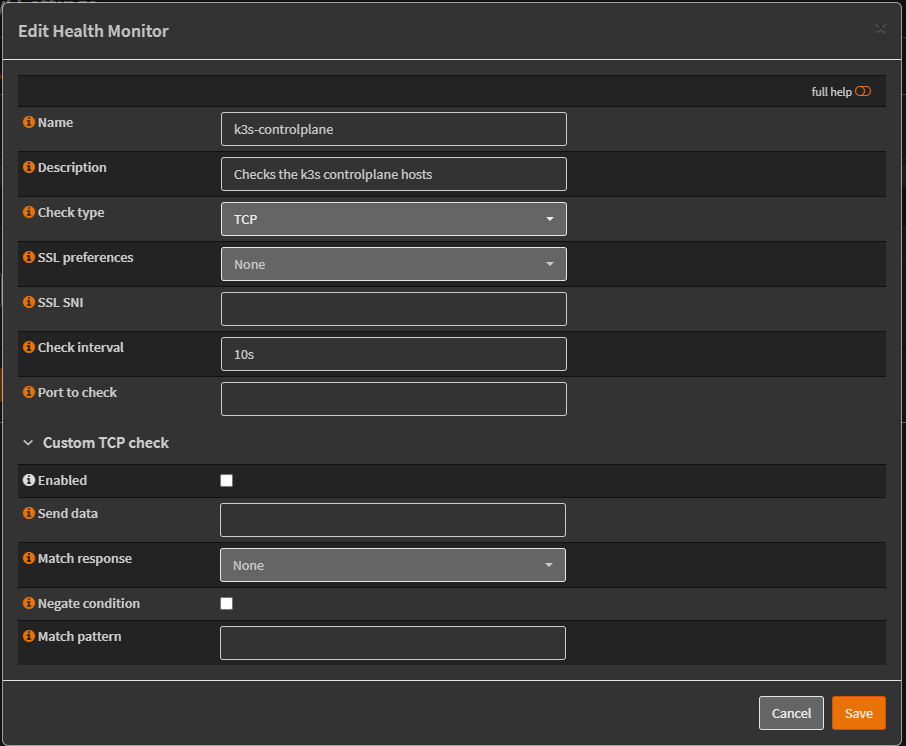
Creating the health monitor:
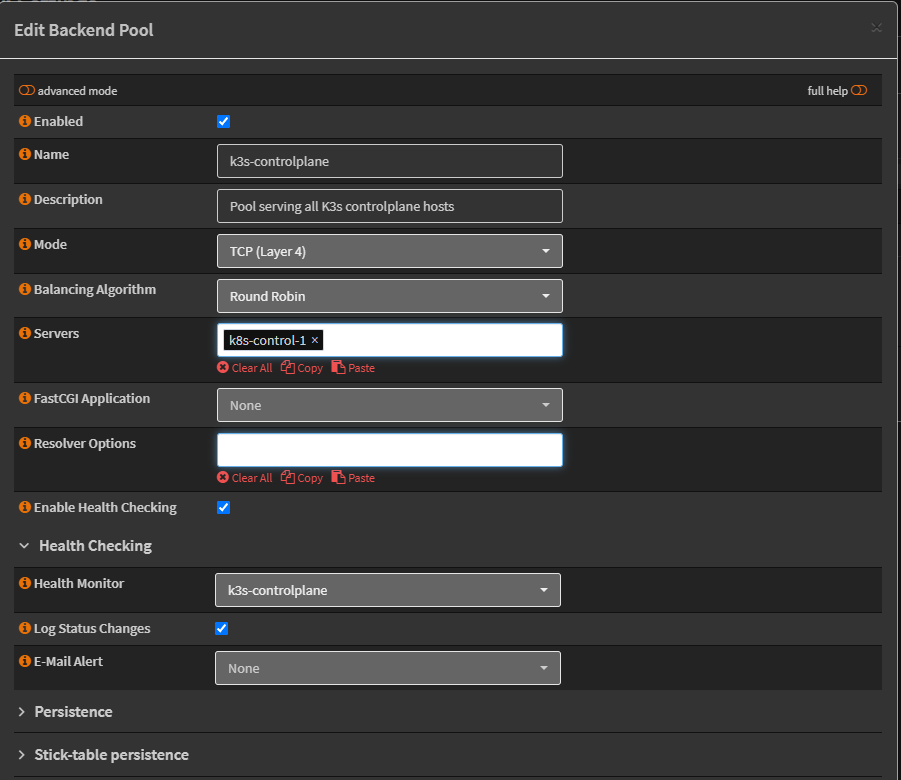
Creating the backend pool:
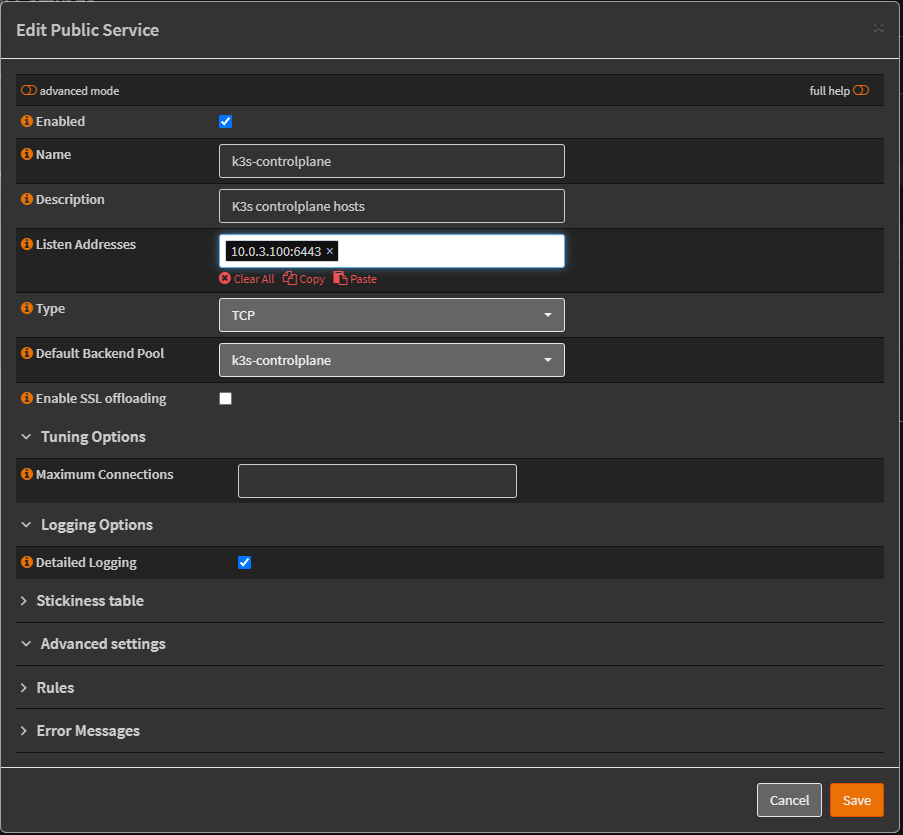
Creating the public service (frontend):
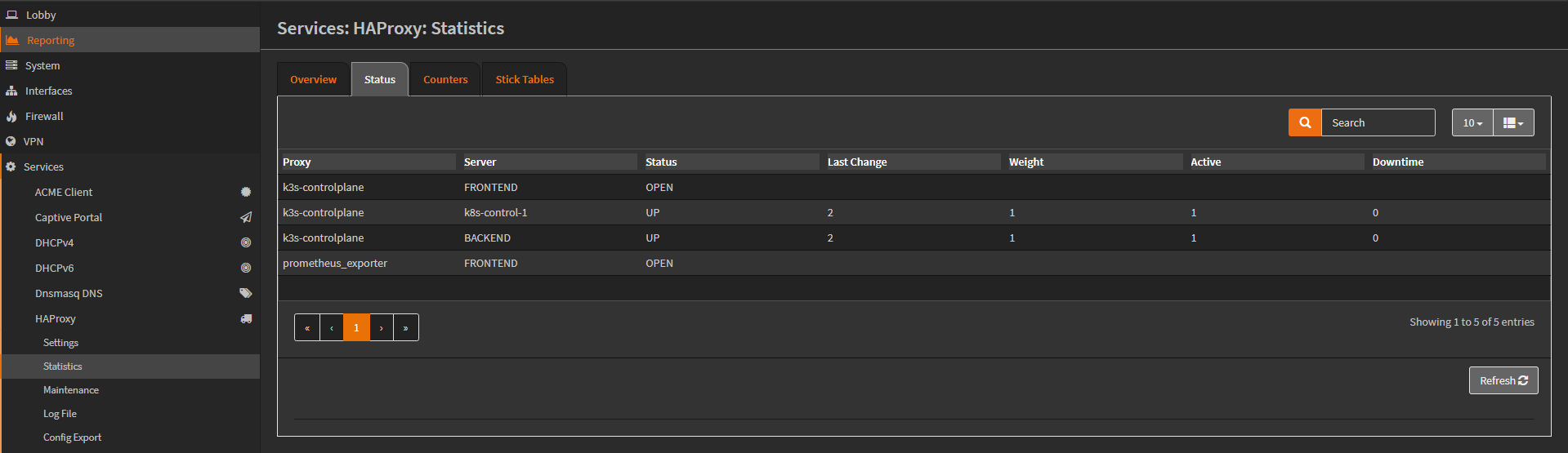
Statistics page:
The Config Export:
# Frontend: k3s-controlplane (K3s controlplane hosts)
frontend k3s-controlplane
bind 10.0.3.100:6443 name 10.0.3.100:6443
mode tcp
default_backend k3s-controlplane
# logging options
option tcplog
# Backend: k3s-controlplane (Pool serving all K3s controlplane hosts)
backend k3s-controlplane
option log-health-checks
# health check: k3s-controlplane
mode tcp
balance roundrobin
server k8s-control-1 10.0.3.2:6443 check inter 10s
This is everything that is required until the cluster is expanded with more control plane nodes. I’ll do that in the next section.
Changing the existing single-node cluster to HA with embedded etcd
The documentation on this is pretty good. The existing control plane node (k8s-control-1) will be the node bootstrapping the cluster.
Inventory of the Ansible playbook:
[all:vars]
...
# VIP
k3s_control_plane_vip=10.0.3.100
# There will only ever be one host designated to
# bootstrap the cluster
[initial_k3s_server]
10.0.3.2 node_name=k8s-control-1
[remaining_k3s_servers]
10.0.3.7 node_name=k8s-control-2
10.0.3.8 node_name=k8s-control-3
I added a new role: k3s-initial-server, with the following tasks:
- name: Check if k3s is already installed
ansible.builtin.stat:
path: /usr/local/bin/k3s
register: k3s
- name: Bootstrap k3s cluster with etcd
become: yes
shell: "{{ k3s_install_script_dest }}"
environment:
INSTALL_K3S_CHANNEL: "{{ k3s_channel }}"
INSTALL_K3S_VERSION: "{{ k3s_version }}"
# I extracted the existing token from /var/lib/rancher/k3s/server/token
# and set it as a variable to be passed into the Ansible playbook
K3S_TOKEN: "{{ k3s_token }}"
K3S_NODE_NAME: "{{ node_name }}"
# Set the --tls-san to the VIP
INSTALL_K3S_EXEC: "--disable servicelb --tls-san {{ k3s_control_plane_vip }} --cluster-init"
when: (reinstall | bool) or not k3s.stat.exists
The role is delegated to the group initial_k3s_server:
- name: Setup initial k3s server
hosts: initial_k3s_server
roles:
- { role: k3s-initial-server, tags: [k3s-baseline] }
Running the Ansible playbook with -e reinstall=true changes the existing control plane installation from SQLite to etcd:
NAME STATUS ROLES AGE VERSION
k8s-control-1 Ready control-plane,etcd,master 296d v1.24.17+k3s1
At this stage I have only reinstalled
k8s-control-1, none of the worker nodes were reinstalled until after I confirmed that the HAProxy setup was working.
The configuration file /etc/rancher/k3s/config.yaml now has the new VIP in it:
k8s-control-1:~$ cat /etc/rancher/k3s/config.yaml
token: X
tls-san:
- 10.0.3.100
This was not enough to update the existing certificates. Simply downloading the new kubeconfig from k8s-control-1 and changing the IP address to the VIP produced this:
$ kubectl config view
...
clusters:
- cluster:
...
server: https://10.0.3.100:6443
...
$ kubectl get pods -A
Unable to connect to the server: tls: failed to verify certificate: x509: certificate is valid for 10.0.3.2, 10.43.0.1, 127.0.0.1, ::1, not 10.0.3.100
I had to delete the old certificates and generate new ones. The solution comes from this comment:
On k8s-control-1:
k8s-control-1:~$ sudo k3s kubectl -n kube-system delete secrets/k3s-serving
k8s-control-1:~$ sudo mv /var/lib/rancher/k3s/server/tls/dynamic-cert.json /tmp/dynamic-cert.json
k8s-control-1:~$ sudo systemctl restart k3s
# After verifying that it works
k8s-control-1:~$ rm /tmp/dynamic-cert.json
After downloading the kubeconfig from k8s-control-1 again and changing the IP address to the VIP, I was able to access the control plane over TLS:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-control-1 Ready control-plane,etcd,master 293d v1.24.17+k3s1
...
The new control plane nodes are initialized using the old role k3s-servers with some changes:
- name: Check if k3s is already installed
ansible.builtin.stat:
path: /usr/local/bin/k3s
register: k3s
- name: Install k3s on server
become: yes
shell: "{{ k3s_install_script_dest }}"
environment:
INSTALL_K3S_CHANNEL: "{{ k3s_channel }}"
INSTALL_K3S_VERSION: "{{ k3s_version }}"
K3S_TOKEN: "{{ k3s_token }}"
# There will only ever be one host in this group
K3S_URL: "https://{{ groups['initial_k3s_server'] | first }}:6443"
K3S_NODE_NAME: "{{ node_name }}"
# This needs to include `server` first so it does not get registered as an agent. Set the --tls-san to the VIP
INSTALL_K3S_EXEC: "server --disable servicelb --tls-san {{ k3s_control_plane_vip }}"
when: (reinstall | bool) or not k3s.stat.exists
The role is delegated to the group remaining_k3s_servers:
- name: Setup remaining k3s servers
hosts: remaining_k3s_servers
roles:
- { role: k3s-servers, tags: [k3s-baseline] }
This installs K3s and joins the remaining control plane nodes to the cluster:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-control-1 Ready control-plane,etcd,master 297d v1.24.17+k3s1
k8s-control-2 Ready control-plane,etcd,master 40h v1.24.17+k3s1
k8s-control-3 Ready control-plane,etcd,master 40h v1.24.17+k3s1
...
The new control plane nodes were then added to the setup in HAProxy.
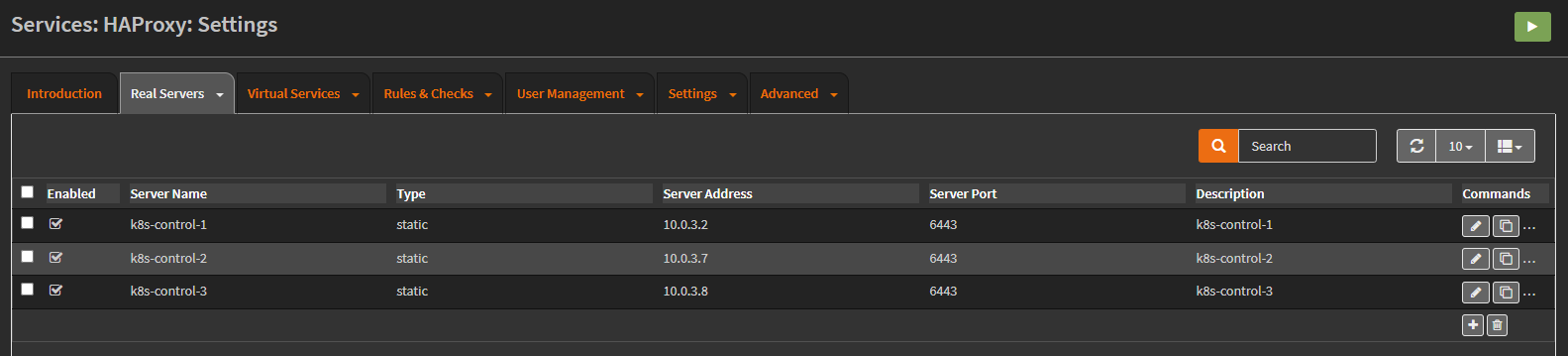
Creating the hosts:
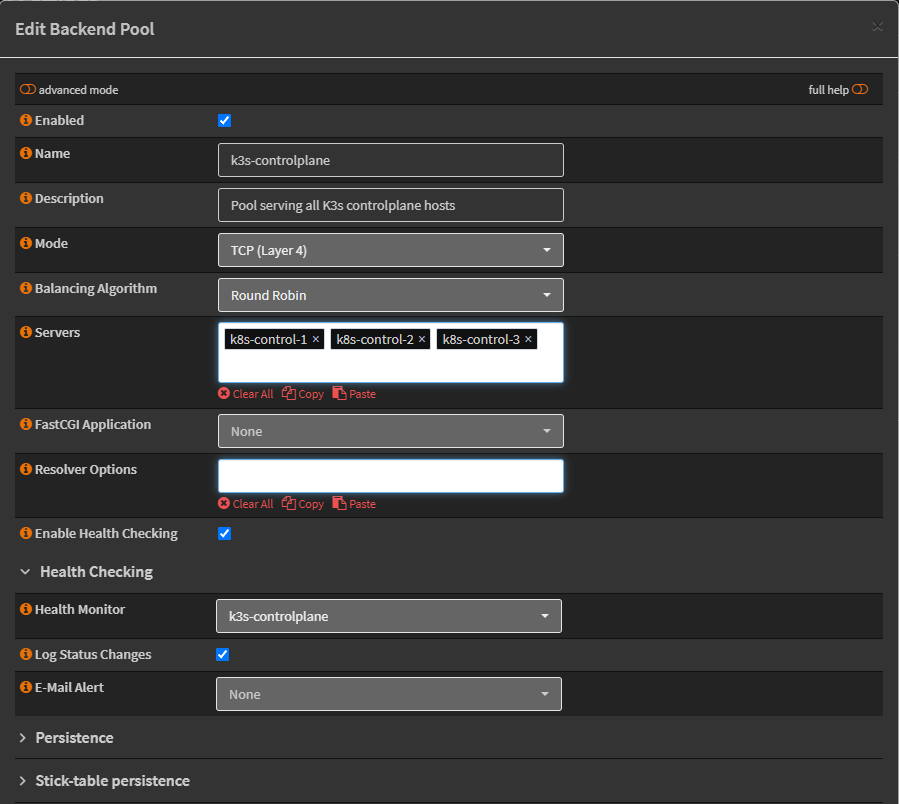
Updating the backend pool:
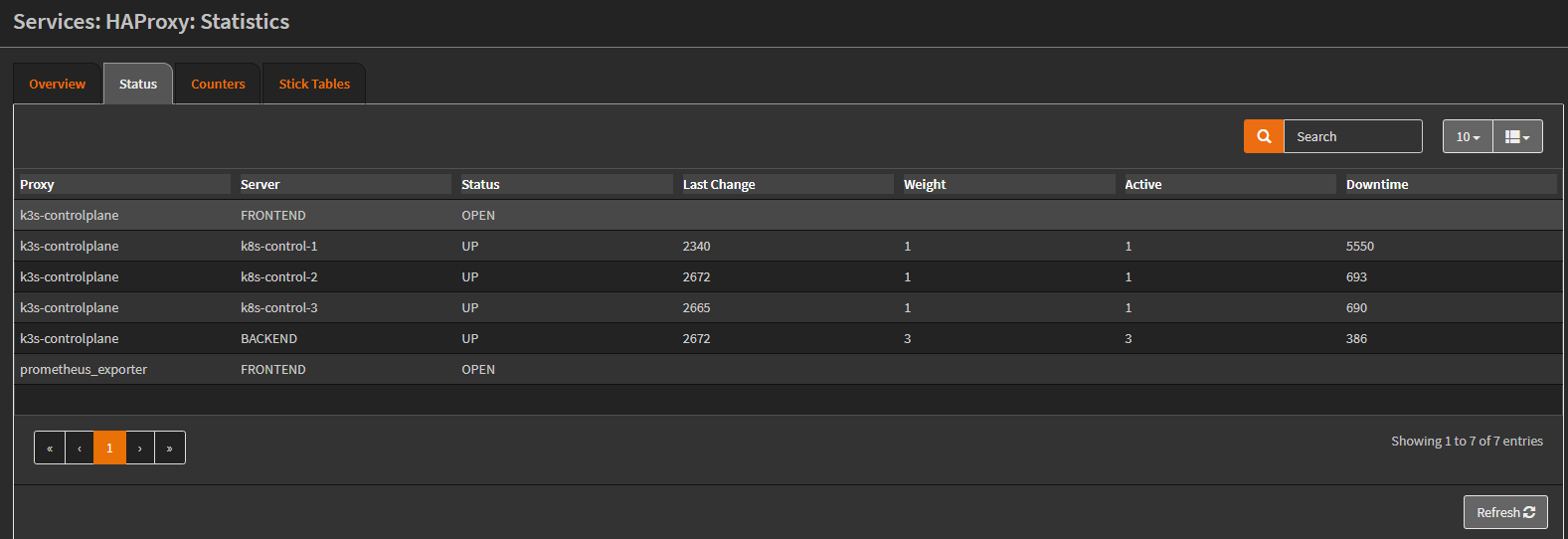
Statistics page:
The Config Export:
# Frontend: k3s-controlplane (K3s controlplane hosts)
frontend k3s-controlplane
bind 10.0.3.100:6443 name 10.0.3.100:6443
mode tcp
default_backend k3s-controlplane
# logging options
option tcplog
# Backend: k3s-controlplane (Pool serving all K3s controlplane hosts)
backend k3s-controlplane
option log-health-checks
# health check: k3s-controlplane
mode tcp
balance roundrobin
server k8s-control-1 10.0.3.2:6443 check inter 10s
server k8s-control-2 10.0.3.7:6443 check inter 10s
server k8s-control-3 10.0.3.8:6443 check inter 10s
With the HAProxy setup confirmed working, I went on to reinstall the workers and join them to the cluster using the new VIP. Role k3s-agents:
- name: Check if k3s is already installed
ansible.builtin.stat:
path: /usr/local/bin/k3s
register: k3s
- name: Install k3s on agent
become: yes
shell: "{{ k3s_install_script_dest }}"
environment:
INSTALL_K3S_CHANNEL: "{{ k3s_channel }}"
INSTALL_K3S_VERSION: "{{ k3s_version }}"
K3S_TOKEN: "{{ k3s_token }}"
# The VIP is used instead of k8s-control-1 IP address
K3S_URL: "https://{{ k3s_control_plane_vip }}:6443"
K3S_NODE_NAME: "{{ node_name }}"
when: (reinstall | bool) or not k3s.stat.exists
/etc/systemd/system/k3s-agent.service.env after reinstalling the workers:
...
K3S_URL='https://10.0.3.100:6443'
I was expecting a reinstall with a new K3S_URL to break the existing setup in some way, but it didn’t. Everything worked and none of the workloads seemed to have been impacted. This made me suspicious enough that I had to verify the new setup.
I ended up:
- Draining and shutting down
k8s-cluster-1 - Performing operations that would trigger traffic in the cluster, such as deleting pods
- Observing that workers still functioned as normal
I considered the setup verified after this.
Enabling the HAProxy plugin Prometheus exporter
I enabled the Prometheus exporter to gather metrics from HAProxy:
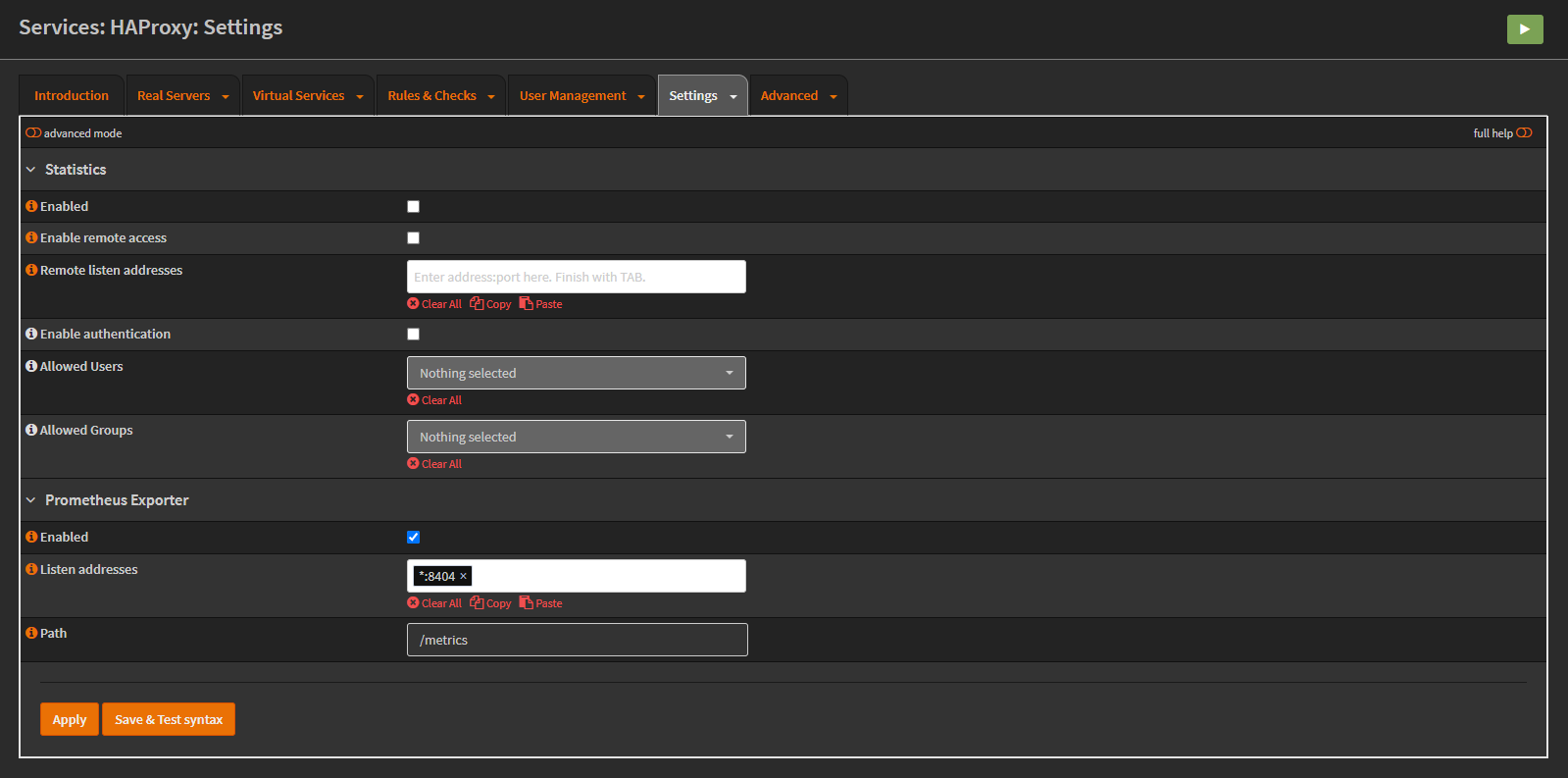
The Config Export:
frontend prometheus_exporter
bind *:8404
mode http
http-request use-service prometheus-exporter if { path /metrics }
Updating the Prometheus scrape config:
- job_name: 'k3s-controlplane-haproxy'
scrape_interval: 15s
static_configs:
- targets:
- '10.0.3.100:8404'
I imported the HAProxy 2 Grafana dashboard. Displaying metrics from the k3s-controlplane services:
The amount of traffic passing through HAProxy seemed very low compared to that I was expecting:
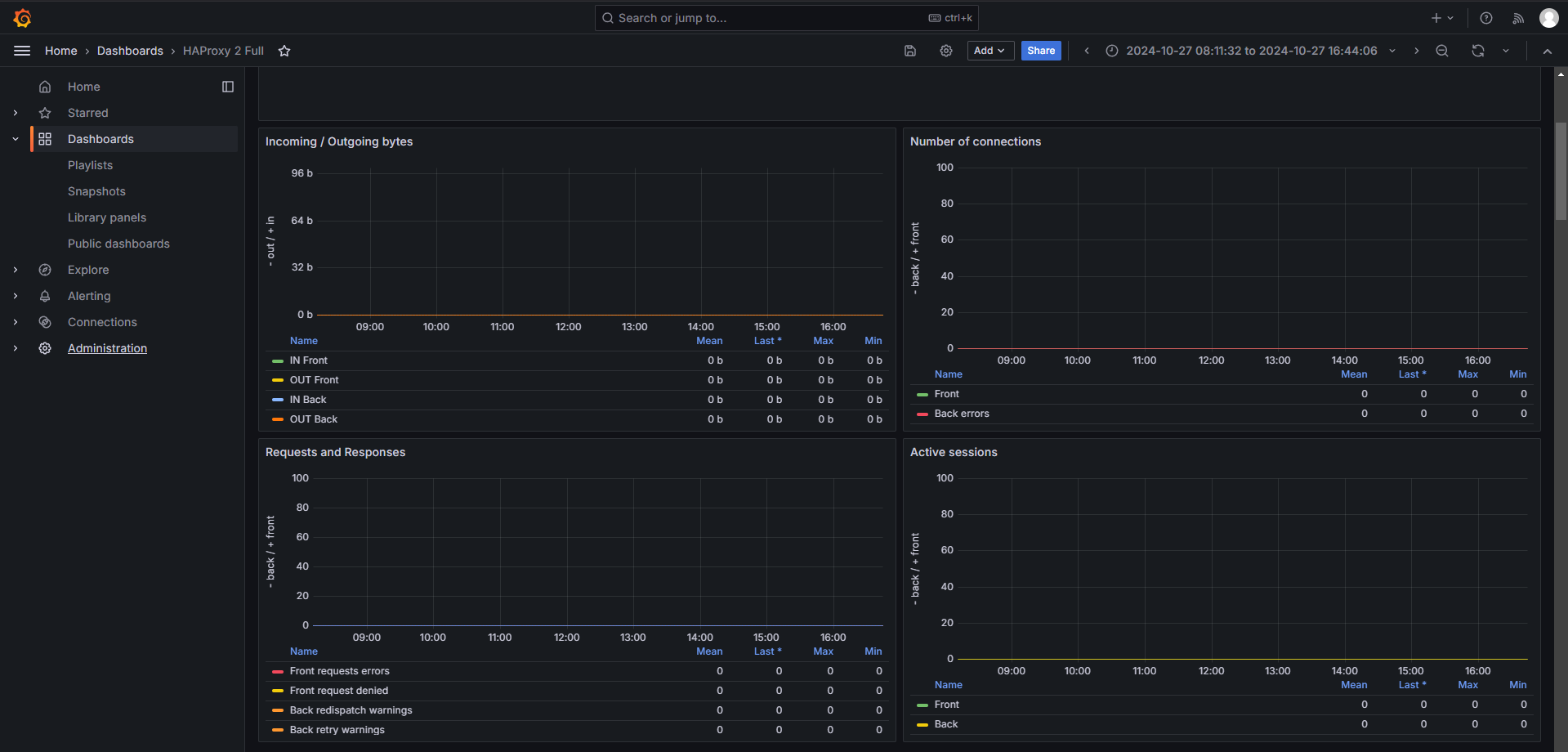
I could not get this to compute. There is enough traffic between the worker nodes and the control plane that no traffic for such a long period of time means something isn’t right. I verified earlier that traffic was not exclusively being sent to k8s-control-1 after the reinstall.
I checked the logs of k8s-worker-1 and discovered this:
Oct 27 08:45:36 k8s-worker-1 k3s[2406293]: time="2024-10-27T08:45:36Z" level=info msg="Removing server from load balancer k3s-agent-load-balancer: 10.0.3.2:6443"
That seemed strange, the worker nodes aren’t configured with any knowledge of the setup in HAProxy.
Turns out that K3s agents don’t actually use the Fixed Registration Address (the VIP in this case) for anything beyond initial registration, or as a failover if all control plane nodes are down: https://docs.k3s.io/architecture#fixed-registration-address-for-agent-nodes
In the high-availability server configuration, each node can also register with the Kubernetes API by using a fixed registration address, as shown in the diagram below.
After registration, the agent nodes establish a connection directly to one of the server nodes.
Which makes perfect sense as to why there is close to no traffic going through the HAProxy frontend after the initial registration. There are some issues that clarify this:
- https://github.com/k3s-io/k3s/discussions/4488#discussioncomment-1719009
- https://github.com/k3s-io/k3s/discussions/10991#discussioncomment-10848102
And sure enough, a restart of the k3s-agent.service produced the following:
Oct 27 18:57:32 k8s-worker-1 k3s[327800]: time="2024-10-27T18:57:32Z" level=info msg="Starting k3s agent v1.24.17+k3s1 (026bb0ec)"
Oct 27 18:57:32 k8s-worker-1 k3s[327800]: time="2024-10-27T18:57:32Z" level=info msg="Adding server to load balancer k3s-agent-load-balancer: 10.0.3.100:6443"
Oct 27 18:57:32 k8s-worker-1 k3s[327800]: time="2024-10-27T18:57:32Z" level=info msg="Adding server to load balancer k3s-agent-load-balancer: 10.0.3.7:6443"
Oct 27 18:57:32 k8s-worker-1 k3s[327800]: time="2024-10-27T18:57:32Z" level=info msg="Adding server to load balancer k3s-agent-load-balancer: 10.0.3.8:6443"
Oct 27 18:57:32 k8s-worker-1 k3s[327800]: time="2024-10-27T18:57:32Z" level=info msg="Adding server to load balancer k3s-agent-load-balancer: 10.0.3.2:6443"
Oct 27 18:57:32 k8s-worker-1 k3s[327800]: time="2024-10-27T18:57:32Z" level=info msg="Removing server from load balancer k3s-agent-load-balancer: 10.0.3.100:6443"
Oct 27 18:57:32 k8s-worker-1 k3s[327800]: time="2024-10-27T18:57:32Z" level=info msg="Running load balancer k3s-agent-load-balancer 127.0.0.1:6444 -> [10.0.3.2:6443 10.0.3.7:6443 10.0.3.8:6443] [default: 10.0.3.100:6443]"
With that cleared up, I merged the changes to the playbook and called it a day.
Conclusion
One downside of the current setup is that I’m placing more responsibility in OPNsense by running HAProxy there. I don’t have a secondary instance so there is no failover if OPNsense goes down. In most cases I opt for using Terraform and Ansible, now I’m relying on UI configuration steps with offsite backups in the event of failure.
That being said, the certificates in the cluster are already configured with the VIP. If I ever change my mind and want to convert from OPNsense to something else, as long as whatever load balancer I end up using serves the frontend over the same IP address I should be fine.
It’s great to finally have proper HA setup for the control plane.