Writing a simple build automation tool
I originally wrote the draft of this post back in April without publishing it. At the time I didn’t think the post had a clear enough direction and ended up abandoning it. I decided to rewrite portions of it and publish it to capture some of the experiences I had during the project.
Being a fan of automation and pipelines, I’ve wanted to try and write a simple build automation tool similar to Jenkins and Gitlab CI/CD for some time. I had some time on my hands and decided to write a simple version as a learning experience.
Note: There are several aspects related to security not addressed due to the limited scope of the project. Don’t copy this.
Terminology
Some terminology before diving into the details.
- Agent/Build-Agent, client-side application which dequeues jobs from the server and executes commands on the host operating system
- Server/Build-Server, server-side application that receives instructions to queue builds, converts YAML into database entities and authorizes API calls from agents
Requirements
I defined some functional and technical requirements to have a baseline that wouldn’t let me end up in feature-creep mode.
One of the primary goals I had in mind was to use the Native Image Builder feature in GraalVM to AOT-compile the build agents as standalone binaries, similar to the Gitlab CI/CD runners written in Go.
Functional
- As a user I want to be able to queue a build for a specific git repository and commit-ref
- As a user I want to tail the logs of the commands executed on the agent via the server
Technical
- Agent must be possible to distribute as a standalone binary
- Agent must be able to dequeue jobs from the server
- Agent must be able to execute commands, which are converted from instructions specified in a file using YAML checked into the git repository
- Agent must be able to communicate its status back to the server continuously (check-in/liveness-probe)
Result
Ironing out the requirements into technical specifications:
Server:
- Register a git repository as a source for builds that can be queued
- Queue builds for a registered git repository and commit-ref
- Register agents
- Verify agent registration and mark an agent as eligible for dequeueing jobs
- Enforce authorization of only agents being able to call certain APIs
- Dequeue jobs
- Push log statements for steps
- Complete steps
- Fail steps
- Check-in/liveness-probe
- Convert a specific YAML-file within a git repository into database entities representing stages, jobs and steps
Agent:
- Dequeue jobs from the server
- Checkout the files within the commit specified in the queued build
- Execute each step defined in a job sequentially
- Stream the output of each command in a step back to the server
- Continuously report back status to the server, a check-in/liveness-probe
- Unregister itself upon receiving signal to terminate the process from the OS
Development stack
I decided to stick with a known stack since learning a new language or framework wasn’t the focus of the project. In the end I settled for Kotlin, Gradle, Spring Boot, Micronaut and simple REST-based APIs using HTTP and JSON. Micronaut was used for the agent since Spring native had not been officially released at the time.
In short, this became the stack for both components:
Server:
- Kotlin
- Spring Boot
Agent:
- Kotlin
- Micronaut
Development process
Modeling the database
This is roughly what ended up as the final database structure in the end:
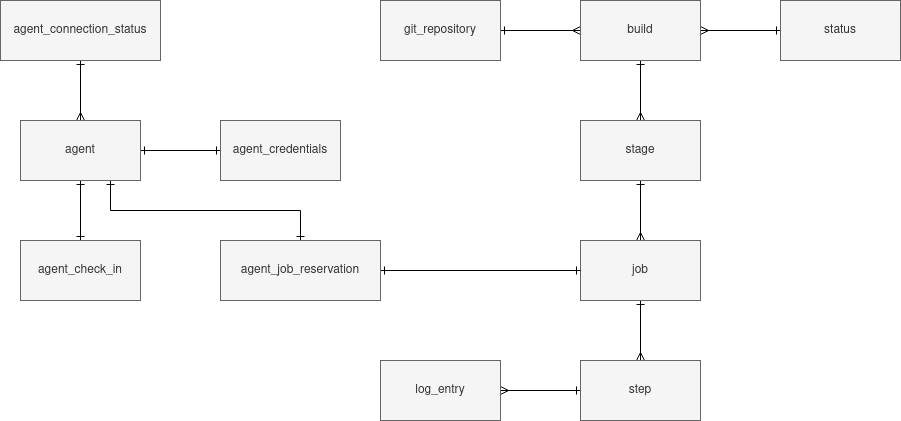
A Step is the lowest unit of work and is the combination of a name and a command to execute
on the host OS of a build agent. An agent dequeues and reserves a Job containing steps. Stage
represents a collection of Jobs but this wasn’t used much and could have been skipped.
LogEntry was introduced later, it captures the output of each command within
a step that is executed.
To have a mechanism for knowing if agents are still responding there is AgentCheckIn. It
has a 1-1 relationship with an agent and keeps track of the last time the agent reported back.
AgentCredentials is for knowing which agent is dequeueing and also reserving a Job.
The reservation mechanism and the credentials work together to ensure that only the agent
responsible for the job is able to do things like push log entries connected to steps and
complete steps in a job.
Defining the YAML file format
I wanted the format of build definitions to be simple. A git repository has a file in the root
directory named ci.yml which is fetched by the server from a specific commit-ref in the repository.
The content of the file is mapped into database entities representing a build.
Example build definition:
stages:
- name: Stage1
jobs:
- name: Job1
steps:
- name: Step1
command: echo "hello world" && echo "Hi"
- name: Make script executable
command: chmod +x long_running_script_with_continuous_echo.sh
- name: executeScript
command: ./long_running_script_with_continuous_echo.sh
This ends up converted into a series of entities in the database with an index tracking its order relative to its parent entity:
Build
|
|
Stage1
- index: 0
|
|
Job1
- index: 0
/ | \
Step1 ------/ | \------ executeScript
- index: 0 | - index: 2
- command | - command
|
"Make script executable"
- index: 1
- command
The cmd property is just a varchar containing the string of the command
stored directly in the entity (again, security is not the focus, don’t
do this).
Compiling GraalVM native-images for ARM
The initial idea was to deploy agents to a Kubernetes cluster running on top of a series of Raspberry Pis. This requires compiling the native-image for ARM32/64 (ARM64 in my case).
Initially I thought of setting up a dedicated Github Actions runner on a Raspberry Pi to delegate building the native-image itself as part of a workflow. This would have been the best choice except that I lack a Pi in my cluster with 8GB memory. All attempts at compiling the agent on a 4GB Pi inevitably ended up with the Pi dying due to OOM. This is one of the hurdles when doing AOT-compilation with GraalVM, it needs a lot of resources to produce a native-image.
After trying a native compilation on the Pi itself I turned to using Buildx for cross-compilation to ARM on x86. This produced some errors, as several tools in the Dockerfile of the native image relied on toolchains only available on x86.
As a last attempt I tried using QEMU to emulate ARM on x86. This also failed and I ended up abandoning the idea of compiling to ARM. Compiling and testing on x86 would have to suffice.
Using the Native Image Builder in a Micronaut-based project was fairly straightforward thanks to the predefined Gradle task.
The final size of the Native Image containing the agent:
$ ls -l --block-size=MB build/native-image/application
-rwxrwxr-x 1 fred fred 73MB april 5 18:35 build/native-image/application
73MB including sources and libraries AOT-compiled into a single binary. To put things in perspective: the source and libraries of an ordinary Kotlin/Gradle project has been compiled into a single standalone binary without any specific changes required.
Compare this to the binary of the Gitlab runner which is about 50MB. The gitlab runner is feature-complete and stands at 23MB less compared to a very simplified version of something similar written by me. Go is still ahead in terms of being able to produce smaller binaries.
While native-images is an exciting new technology, its not without hurdles. There are several libraries that don’t yet support AOT-compilation, and each dependency added requires a full compilation and verification of the binary to ensure it remains functional. The compilation process also requires a lot of resources.
Streaming logs from ProcessBuilder
An implementation detail of the agent I was pleased with was
streaming the output of ProcessBuilder back to the server
continuously as the commands were being executed. The snippets
below capture the key parts of the implementation.
The function responsible for executing commands using ProcessBuilder
and piping the output to the function subprocessOutputCallback:
...
private const val SUCCESSFUL_EXECUTION = 0
private const val timeoutValue: Long = 12
private val timeoutUnit: TimeUnit = TimeUnit.HOURS
/**
* Main point of entry for executing operations
* on host OS of the agent. By default, any process
* which spans longer than the given maximum timeout-value
* of 12 hours is terminated.
*
* @param commands the commands which will be executed against
* the OS provided as an array.
* @param directory (optional) the directory where the commands
* provided will be executed within
* @param subprocessOutputCallback (optional) the callback where
* stdin and stderr of the command is sent to.
* @return result of the operation with the error-code from the OS included
*/
fun executeCommand(
commands: Array<String>,
directory: String? = null,
subprocessOutputCallback: (standardOut: BufferedReader) -> Unit = { }
): ExecutionResult {
val processBuilder = ProcessBuilder(*commands)
directory?.let { processBuilder.directory(File(directory)) }
processBuilder.redirectErrorStream(true)
processBuilder.redirectOutput(ProcessBuilder.Redirect.PIPE)
val process = processBuilder.start()
subprocessOutputCallback(BufferedReader(InputStreamReader(process.inputStream)))
val timeoutExpired = !process.waitFor(timeoutValue, timeoutUnit)
if (timeoutExpired) {
throw ExecutionException("TimeoutExceeded. Terminating")
}
return ExecutionResult(
ok = process.exitValue() == SUCCESSFUL_EXECUTION,
returnCode = process.exitValue()
)
}
This function pushes each line of the output to the server
as a LogEntry connected to a Step:
private fun createOutputCallback(stepId: Long, command: String): (BufferedReader) -> Unit {
val subprocessOutputCallback = { reader: BufferedReader ->
val commandLogEntry = LogEntryRequestBody(stepId = stepId, output = command)
val commandResponse = apiService.appendLogEntry(commandLogEntry)
reader.forEachLine { logLine ->
logger.info(logLine)
val formattedLogLine = logLine.ifBlank { "\n" }
val outputLogEntry = LogEntryRequestBody(stepId = stepId, output = formattedLogLine)
apiService.appendLogEntry(outputLogEntry)
}
logger.info("End output from step with id: {}", stepId)
}
return subprocessOutputCallback
}
Tying it all together:
...
private fun executeStep(step: Step, repositoryPath: String): Boolean {
val logOutputCallback = createOutputCallback(
stepId = step.id,
command = step.command
)
val result = executeStep(
step = step.command,
directory = repositoryPath,
outputCallback = logOutputCallback
)
return handleResult(
result = result,
stepId = step.id
)
}
...
In retrospect the logs should probably have been piped to a file with its own filewatcher that synced the position in the file with the server. Instead the entire output of the command being executed ends up in text columns in the database table, which is not ideal. That being said, streaming the output of the Processbuilder while the commands are being processed is still a nice feature.
Demo
I made a small demo to showcase the queue/dequeue process of builds. The demo uses 1 instance of the server and 2 instances of the agent.
The project id holding reference to the git repository is 1 and the
commit-ref is 12d707c046a0ee526b5e7e05e1e6117afc5accab.
Given the following ci.yml checked into the root of a git repository:
stages:
- name: Stage1
jobs:
- name: Job1
steps:
- name: Make script executable
command: chmod +x long_running_script_with_continuous_echo.sh
- name: executeScript
command: ./long_running_script_with_continuous_echo.sh
- name: Job2
steps:
- name: Make script executable
command: chmod +x hello_world.sh
- name: executeScript
command: ./hello_world.sh
Contents of scripts referenced in ci.yml below:
long_running_script_with_continuous_echo.sh in Job1
#!/bin/bash
echo "Echoing i 3 times"
for i in {1..3}; do
echo "i: $i"
sleep 5
done
hello_world.sh in Job2
#!/bin/bash
echo "Echoing Hello world 3 times"
for i in {1..3}; do
echo "Hello world"
sleep 5
done
File structure in the git repository:
ci.yml
long_running_script_with_continuous_echo.sh
hello_world.sh
The end result:
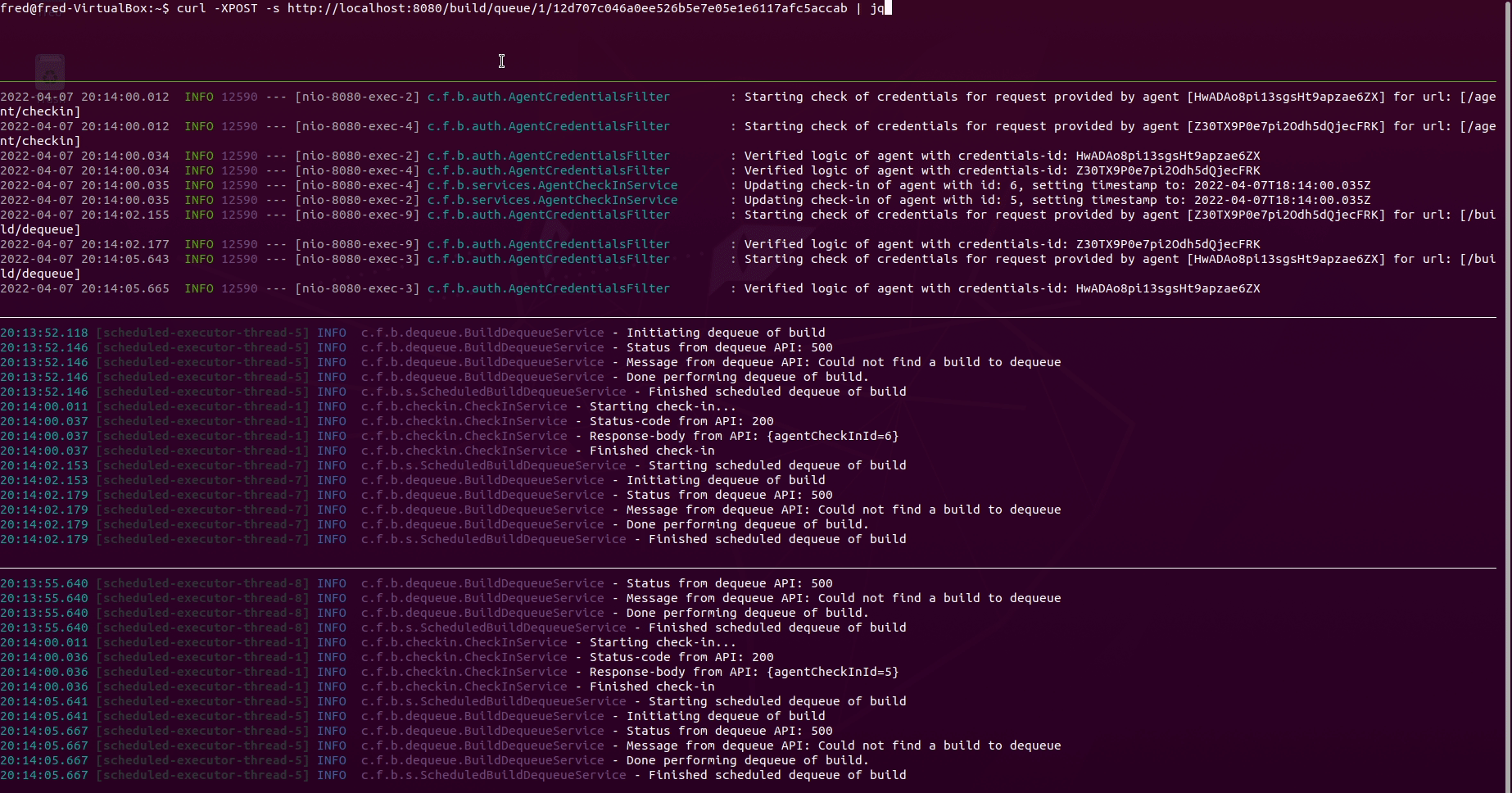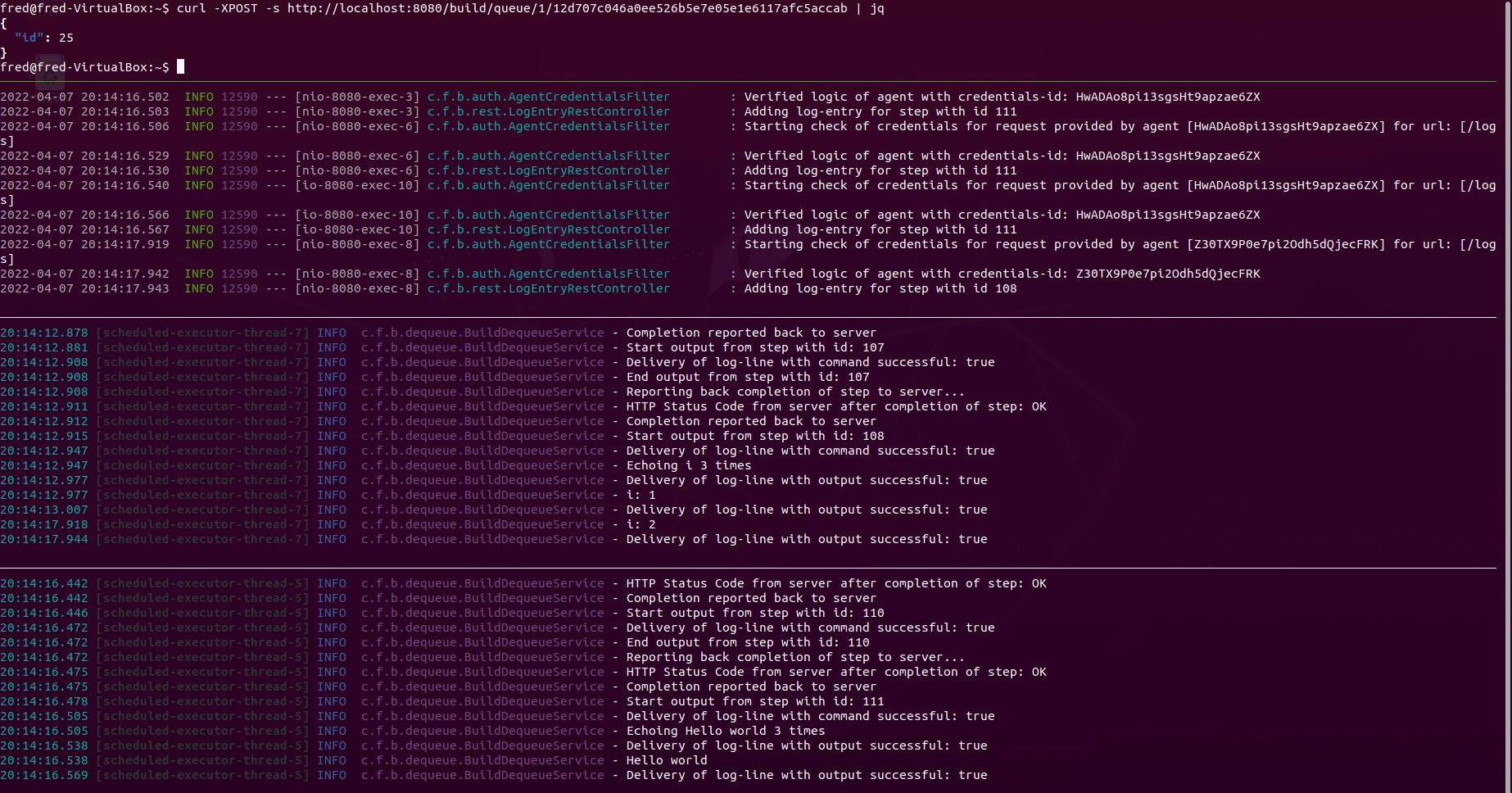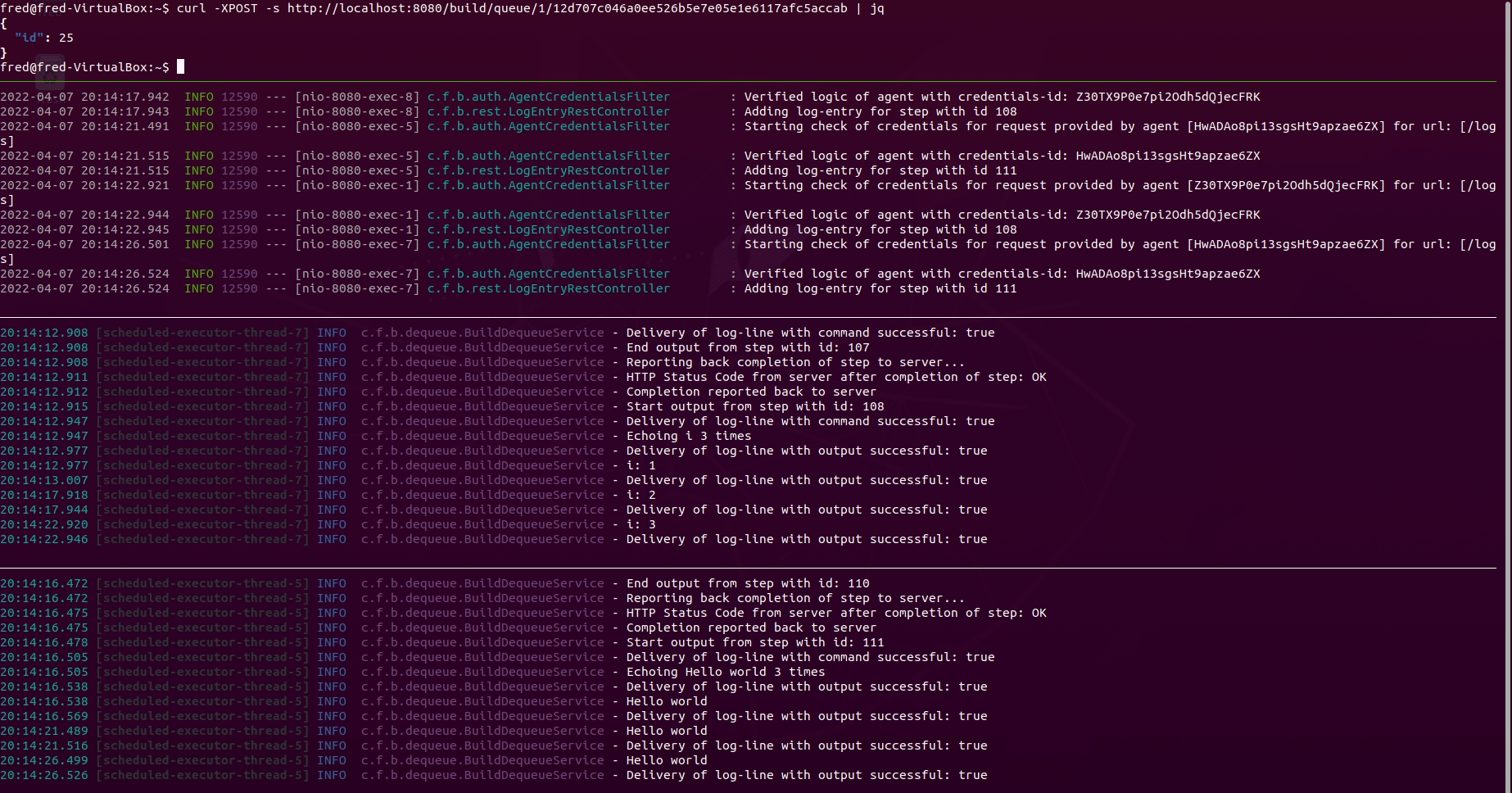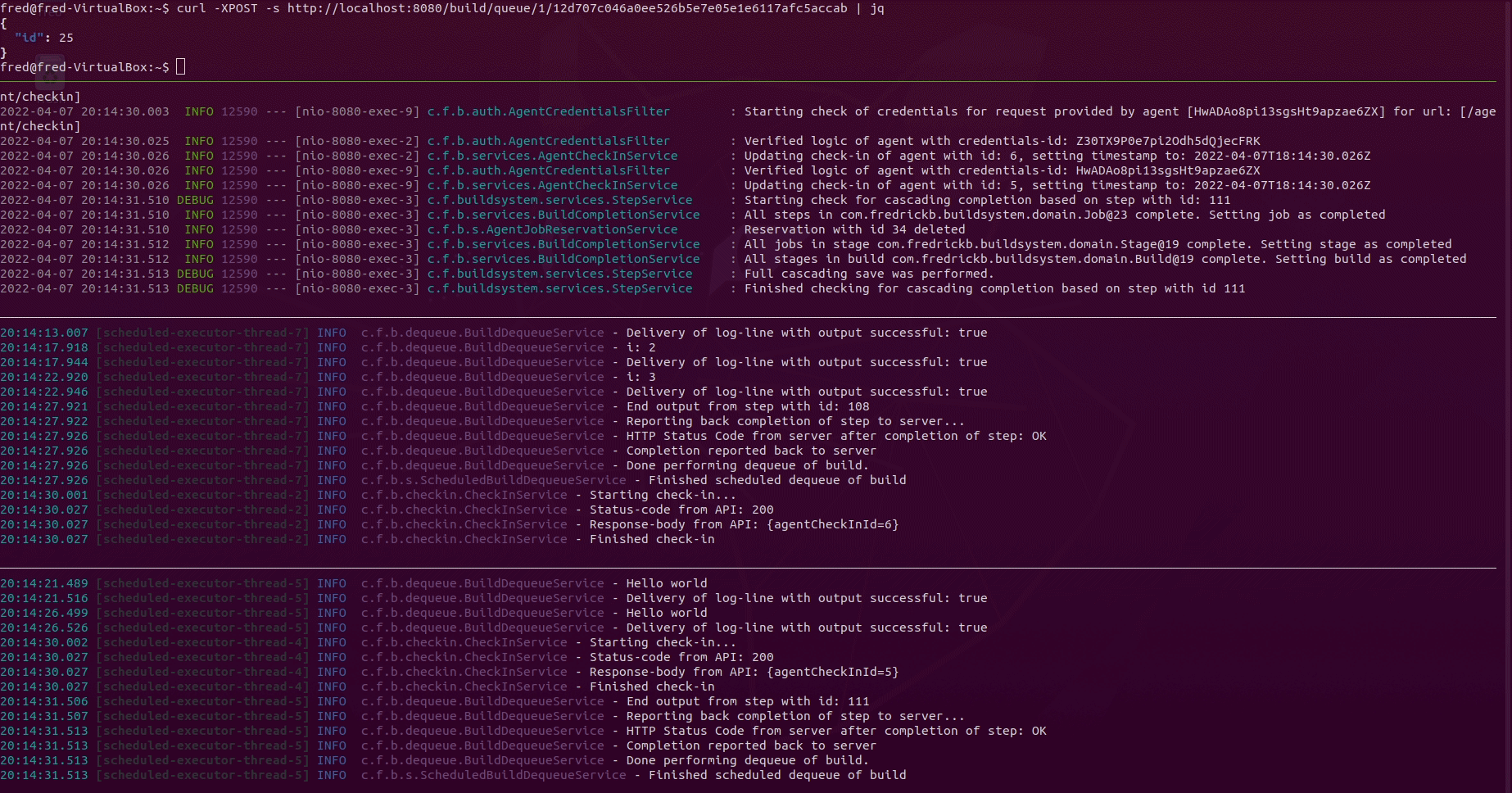
Explaining all panes in the terminal above:
- Pane 1 from the top: Queueing a build using the REST-API with
curlandjq - Pane 2 from the top: Observing the logs of the server converting the content
of
ci.ymlinto database entities. Also shows logs of the interaction via the REST-API between the server and the agents - Pane 3 from the top: Observing logs of agent 1
- Pane 4 from the top: Observing logs of agent 2
Conclusion
In hindsight there is a couple of things I would have done different:
- Trying out the architecture Gitlab CI has and define executors that spawn containers with a predefined docker image and execute the steps of a job within the spawned container.
- Make entities
LogEntryandStepmore loosely coupled by removing the requirement that eachLogEntryneeds a predefinedStepto exist prior to being created. There are certain actions such as cloning a git repository that should not be part of a step itself. This is more of a “meta”-step.
The project still has a few flaws and some edge-cases that are not handled, but overall the prototype works for a few specific use-cases. In the process I like to think I learned more about the inner workings of build automation tools by trying to write a simple version of one.